
Dr. Liu Ren serves as the Vice President and Chief Scientist of Human-Machine Intelligence at Bosch Research North America and the Bosch Center for Artificial Intelligence. In his role, Dr. Ren is at the forefront of advancing assistive and scalable AI technologies. His innovative approach synergizes machine learning, including Foundation Models, with human cognition and Bosch's deep domain knowledge. Dr. Ren's strategic vision is instrumental in driving innovation and growth for the Robert Bosch Corporation, an industry titan with revenues exceeding $90 billion and a global workforce of over 400,000.
As the responsible global head, Dr. Ren leads a network of AI research teams based in key tech hubs, including Silicon Valley, Pittsburgh, Bangalore, Hildesheim, and Renningen. His leadership is key in steering these teams to develop cutting-edge solutions in AI areas such as Computer Vision, Natural Language Processing/LLM, Big Data Visual Analytics, Explainable AI (XAI), Audio Analytics, Cloud Robotics, and specialized AI platforms for sectors like automated driving, advanced driver assistance systems (ADAS), Industry 4.0, and consumer appliances.
Liu has received multiple awards in recognition of his technical expertise and leadership. Additionally, he has played a crucial role in steering the development of multiple key AI products. Furthermore, Liu has made significant contributions to the academic landscape, with a publication record that includes more than 50 papers featured in top-tier AI and computer science conferences and journals. Beyond his publications, he possesses an extensive portfolio of over 50 patents associated with Bosch.
-
• Best Paper Honorable Mention Award in IEEE Visualization 2022: Automatic Edge Case Discovery for Automated Driving (in product)
• Best Paper Award in IEEE Visualization (VAST) 2020: 1st Visual Analytics and XAI Solution for machine learning model validation for Automated Driving (in product)
• CES 2020 Best of Innovation Award : Visual Visor (with Bosch NA Car Multimedia team)
• The World’s Top 10 Industry 4.0 Innovation Award 2019: Bosch Intelligent Glove Product (with Bosch China Automotive Electronics team)
• Best Paper Award in IEEE Visualization (VAST) 2018: Key Visual Analytics Innovation for IoT
• Best Paper Honorable Mention Award in IEEE Visualization 2016: 1st Visual Analytics Innovation for Smart Manufacturing (I4.0) (in product)
-
Liu received his Ph.D. and M.Sc. degrees in Computer Science from Carnegie Mellon University's Computer Science Department and earned his B.Sc. in Computer Science from Zhejiang University, China, after studying in the elite Chu Kochen Honors College program there.
Recent Highlights
-
![VLP: Vision Language Planning for Autonomous Driving]()
Chenbin Pan, Burhan Yaman, Tommaso Nesti, Abhirup Mallik, Alessandro G Allievi, Senem Velipasalar, Liu Ren. “VLP: Vision Language Planning for Autonomous Driving”, The Conference on Computer Vision and Pattern Recognition 2024 (CVPR 2024).
-
![CLIP-BEVFormer]()
Chenbin Pan, Burhan Yaman, Senem Velipasalar, Liu Ren. “CLIP-BEVFormer: Enhancing Multi-View Image-Based BEV Detector with Ground Truth Flow”, The Conference on Computer Vision and Pattern Recognition 2024 (CVPR 2024).
-
![USE: Universal Segment Embeddings for Open-Vocabulary Image Segmentation]()
Xiaoqi Wang, Wenbin He, Xiwei Xuan, Clint Sebastian, Jorge Henrique Piazentin Ono, Xin Li, Sima Behpour, Thang Doan, Liang Gou, Han Wei Shen, Liu Ren. “USE: Universal Segment Embeddings for Open-Vocabulary Image Segmentation” [link coming soon], The IEEE/CVF Conference on Computer Vision and Pattern Recognition 2024 (CVPR 2024).
-
![Behind the Veil: Enhanced Indoor 3D Scene Reconstruction with Occluded Surfaces Completion]()
Su Sun, Cheng Zhao, Yuliang Guo, Ruoyu Wang, Xinyu Huang, Yingjie Victor Chen, Liu Ren. “Behind the Veil: Enhanced Indoor 3D Scene Reconstruction with Occluded Surfaces Completion” [link coming soon], The IEEE/CVF Conference on Computer Vision and Pattern Recognition 2024 (CVPR 2024).
-
![SeaBird: Segmentation in Bird’s View with Dice Loss Improves Monocular 3D Detection of Large Objects]()
Abhinav Kumar, Yuliang Guo, Xinyu Huang, Liu Ren, Xiaoming Liu. “SeaBird: Segmentation in Bird’s View with Dice Loss Improves Monocular 3D Detection of Large Objects” [link coming soon], The IEEE/CVF Conference on Computer Vision and Pattern Recognition 2024 (CVPR 2024).
-
![Lifelong LERF]()
Adam Rashid, Chung Min Kim, Justin Kerr, Letian Fu, Kush Hari, Ayah Ahmad, Kaiyuan Chen, Huang Huang, Marcus Gualtieri, Michael Wang, Christian Juette, Nan Tian, Liu Ren, Ken Goldberg. “Lifelong LERF: Local 3D Semantic Inventory Monitoring Using FogROS2”, The IEEE International Conference on Robotics and Automation (ICRA 2024).
-
![FogROS2-LS]()
Description goes Kaiyuan Chen, Michael Wang, Marcus Gualtieri, Nan Tian, Christian Juette, Liu Ren, John Kubiatowicz, Ken Goldberg. “FogROS2-LS: A Location-Independent Fog Robotics Framework for Latency Sensitive ROS2 Applications” [link coming soon], video, The IEEE International Conference on Robotics and Automation (ICRA 2024).
-
![]()
Suphanut Jamonnak, Jiajing Guo, Wenbin He, Liang Gou, Liu Ren. “OW-Adapter: Human-Assisted Open-World Object Detection with a Few Examples”, The IEEE Visualization Conference 2023 (IEEE VIS 2023) / Transactions on Visualization and Computer Graphics 2024 (IEEE TVCG 2024).
-
![]()
Rakesh R. Menon, Bingqing Wang, Jun Araki, Zhengyu Zhou, Zhe Feng, and Liu Ren. “CoAug: Combining Augmentation of Labels and Labelling Rules”, Findings of the Association for Computational Linguistics 2023 (ACL 2023).









Selected Publications

Chenbin Pan, Burhan Yaman, Tommaso Nesti, Abhirup Mallik, Alessandro G Allievi, Senem Velipasalar, Liu Ren. “VLP: Vision Language Planning for Autonomous Driving”, The IEEE/CVF Conference on Computer Vision and Pattern Recognition 2024 (CVPR 2024).
Summary: VLP introduces a Vision-Language-Planning framework for autonomous driving, leveraging language models to enhance scene understanding and reasoning, achieving state-of-the-art planning performance on the NuScenes dataset with drastically reduced errors and collisions compared to prior methods, while also improving performance in diverse scenarios and new urban environments.

Chenbin Pan, Burhan Yaman, Senem Velipasalar, Liu Ren. “CLIP-BEVFormer: Enhancing Multi-View Image-Based BEV Detector with Ground Truth Flow”, The IEEE/CVF Conference on Computer Vision and Pattern Recognition 2024 (CVPR 2024).
Summary: CLIP-BEVFormer improves multi-view image-based Bird’s Eye View (BEV) detectors using contrastive learning to incorporate ground truth information flow. Experiments on the nuScenes dataset demonstrate substantial improvements over the state-of-the-art for 3D object detection tasks.

Xiaoqi Wang, Wenbin He, Xiwei Xuan, Clint Sebastian, Jorge Henrique Piazentin Ono, Xin Li, Sima Behpour, Thang Doan, Liang Gou, Han Wei Shen, Liu Ren. “USE: Universal Segment Embeddings for Open-Vocabulary Image Segmentation” [link coming soon], The IEEE/CVF Conference on Computer Vision and Pattern Recognition 2024 (CVPR 2024).
Summary: The USE framework addresses the challenge of accurately classifying image segments into text-defined categories in open-vocabulary image segmentation, leveraging a scalable data pipeline and a universal segment embedding model. Experimental studies demonstrate substantial performance improvements over state-of-the-art methods, with potential benefits for downstream tasks like querying and ranking.

Su Sun, Cheng Zhao, Yuliang Guo, Ruoyu Wang, Xinyu Huang, Yingjie Victor Chen, Liu Ren. “Behind the Veil: Enhanced Indoor 3D Scene Reconstruction with Occluded Surfaces Completion” [link coming soon], The IEEE/CVF Conference on Computer Vision and Pattern Recognition 2024 (CVPR 2024).
Summary: Indoor 3D reconstruction method with occluded surface completion is introduced, addressing the neglect of invisible areas in prior state-of-the-art methods. By utilizing learned contextual structure priors and a hierarchical octree representation mechanism with a dual-decoder architecture, the proposed method significantly outperforms existing approaches in terms of the completeness of 3D reconstruction on datasets such as 3D Completed Room Scene (3D-CRS) and iTHOR.

Abhinav Kumar, Yuliang Guo, Xinyu Huang, Liu Ren, Xiaoming Liu. “SeaBird: Segmentation in Bird’s View with Dice Loss Improves Monocular 3D Detection of Large Objects” [link coming soon], The IEEE/CVF Conference on Computer Vision and Pattern Recognition 2024 (CVPR 2024).
Summary: SeaBird addresses the challenge of generalizing monocular 3D detectors to large objects by proposing a segmentation-based approach in bird's-eye view (BEV) using the Dice loss. Demonstrating superior noise-robustness and model convergence for large objects compared to regression losses, SeaBird achieves state-of-the-art results on the KITTI-360 and nuScenes leaderboards, particularly for large objects.

Adam Rashid, Chung Min Kim, Justin Kerr, Letian Fu, Kush Hari, Ayah Ahmad, Kaiyuan Chen, Huang Huang, Marcus Gualtieri, Michael Wang, Christian Juette, Nan Tian, Liu Ren, Ken Goldberg. “Lifelong LERF: Local 3D Semantic Inventory Monitoring Using FogROS2”, video [link coming soon], The IEEE International Conference on Robotics and Automation (ICRA 2024).
Summary: Lifelong LERF introduces a method for local 3D semantic inventory monitoring, enabling a mobile robot to optimize a dense representation of its environment and adapt to changes over time. By leveraging Fog-ROS2 for computational offloading and LERF optimization, it achieves accurate object monitoring, demonstrated in tabletop and Turtlebot experiments.
Kaiyuan Chen, Michael Wang, Marcus Gualtieri, Nan Tian, Christian Juette, Liu Ren, John Kubiatowicz, Ken Goldberg. “FogROS2-LS: A Location-Independent Fog Robotics Framework for Latency Sensitive ROS2 Applications” [link coming soon], video, The IEEE International Conference on Robotics and Automation (ICRA 2024).
Summary: FogROS2-LS is a Fog Robotics framework addressing system latency in cloud robotics by optimizing server selection and offloading compute tasks without modifying ROS2 applications. It dynamically transitions between cloud and edge deployments to meet latency requirements, improving collision avoidance and target tracking performance.


Suphanut Jamonnak, Jiajing Guo, Wenbin He, Liang Gou, Liu Ren. “OW-Adapter: Human-Assisted Open-World Object Detection with a Few Examples”, The IEEE Visualization Conference 2023 (IEEE VIS 2023) / Transactions on Visualization and Computer Graphics 2024 (IEEE TVCG 2024).
Summary: OW-Adapter facilitates pre-trained object detectors to handle open-world object detection by annotating unknown examples with minimal human input, thereby extending detection capabilities and enhancing performance on both known and unknown classes.

Rakesh R. Menon, Bingqing Wang, Jun Araki, Zhengyu Zhou, Zhe Feng, and Liu Ren. “CoAug: Combining Augmentation of Labels and Labelling Rules”, Findings of the Association for Computational Linguistics 2023 (ACL 2023).
Summary: CoAug introduces a co-augmentation framework for improving few-shot and rule-augmentation models in Named Entity Recognition tasks. By combining neural model predictions and rule-based annotations, CoAug leverages the strengths of both approaches, achieving superior performance compared to strong weak-supervision-based NER models on various datasets.

Xin Li, Sima Behpour, Thang Doan, Wenbin He, Liang Gou, Liu Ren. “UP-DP: Unsupervised Prompt Learning for Data Pre-Selection with Vision-Language Models”, video, Neural Information Processing Systems 2023 (NeurIPS 2023).
Summary: UP-DP leverages Foundation Models (e.g., BLIP-2) to select a few high data points for various ML applications such as ML model adaption for domains and Foundation Model distillation even without knowing the down-streaming tasks in advance. It is an unsupervised prompt learning approach utilizing joint vision and text features, achieves up to a 20% performance gain in data pre-selection across seven benchmark datasets.
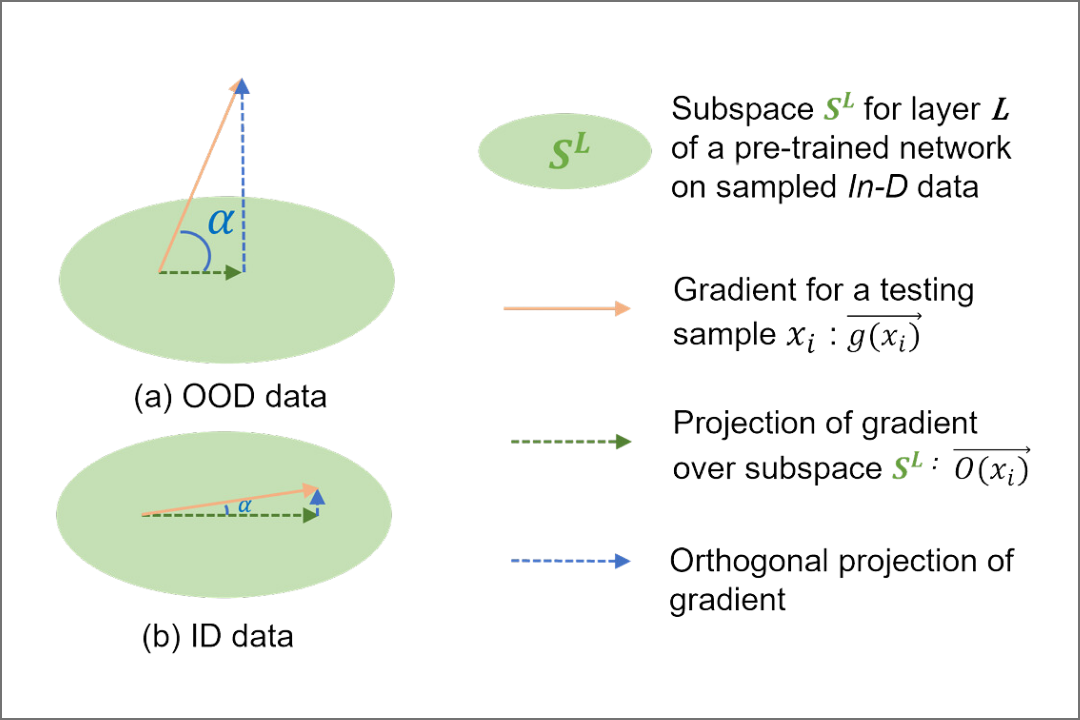
Sima Behpour, Thang Doan, Xin Li, Wenbin He, Liang Gou, Liu Ren. “GradOrth: A Simple yet Efficient Out-of-Distribution Detection with Orthogonal Projection of Gradients”, video, Neural Information Processing Systems 2023 (NeurIPS 2023).
Summary: GradOrth, a novel approach for detecting out-of-distribution (OOD) data in machine learning models with a just few lines of codes. Emphasizing lower-rank subspace considerations, it achieves up to an 8% reduction in the average false positive rate at a 95% true positive rate (FPR95) compared to current state-of-the-art methods, using just a few lines of code.

Yunhao Ge, Hong-Xing Yu, Cheng Zhao, Yuliang Guo, Xinyu Huang, Liu Ren, Laurent Itti, Jiajun Wu. “3D Copy-Paste: Physically Plausible Object Insertion for Monocular 3D Detection”, Neural Information Processing Systems 2023 (NeurIPS 2023).
Summary: This work introduces a physically plausible method for augmenting real indoor scenes with virtual objects, improving the diversity of datasets for monocular 3D object detection and achieving state-of-the-art performance.

Wenbin He, Suphanut Jamonnak, Liang Gou, Liu Ren. “CLIP-S4: Language-Guided Self-Supervised Semantic Segmentation”, video, The IEEE/CVF Conference on Computer Vision and Pattern Recognition 2023 (CVPR highlight 2023).
Summary: CLIP-S4 introduces a self-supervised approach for semantic segmentation without human annotations or known classes, leveraging vision-language models and achieving superior performance in unknown class recognition.
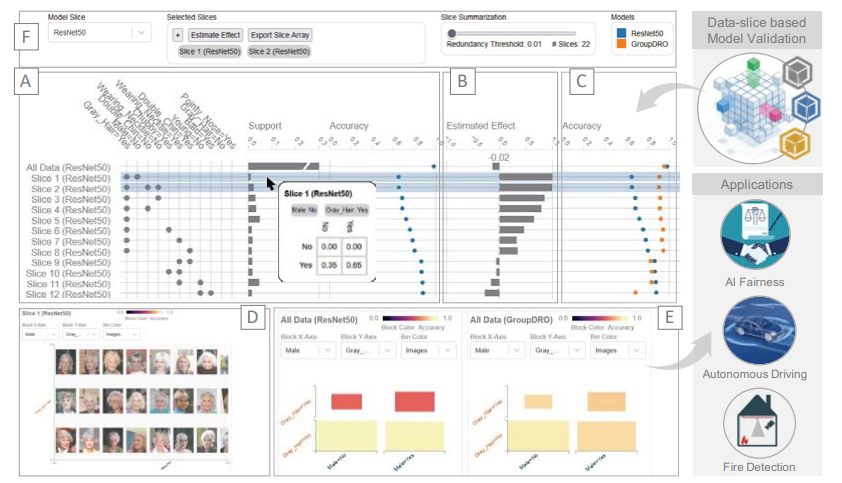
Xiaoyu Zhang, Jorge Piazentin Ono, Huan Song, Liang Gou, Kwan-Liu Ma, and Liu Ren. "SliceTeller: A Data Slice-Driven Approach for Machine Learning Model Validation", short video, long video, IEEE Transactions on Visualization and Computer Graphics 2022 (IEEE VIS 2022, Best Paper Honorable Mention Award).
Summary: A novel tool for debugging and improving machine learning models driven by critical data slices, enabling users to identify problematic data slices, understand model failures, and optimize model performance for real-world applications.

Yuyan Li, Yuliang Guo, Zhixin Yan, Xinyu Huang, Ye Duan, and Liu Ren. "Omnifusion: 360 Monocular Depth Estimation via Geometry-Aware Fusion", video, IEEE/CVF Conference on Computer Vision and Pattern Recognition 2022 (IEEE CVPR Oral 2022).
Summary: OmniFusion is a 360 monocular depth estimation pipeline that handles spherical distortion using tangent images, geometry-aware feature fusion, self-attention-based transformer, and iterative depth refinement, achieving state-of-the-art performance.

Nathaniel Merrill, Yuliang Guo, Xingxing Zuo, Xinyu Huang, Stefan Leutenegger, Xi Peng, Liu Ren, and Guoquan Huang. "Symmetry and Uncertainty-Aware Object SLAM for 6dof Object Pose Estimation", IEEE/CVF Conference on Computer Vision and Pattern Recognition 2022 (IEEE CVPR 2022).
Summary: A keypoint-based SLAM framework for globally consistent 6DoF pose estimates, utilizing SLAM camera pose information and a semantic keypoint network to predict Gaussian covariance for robustness, achieving competitive performance and real-time speed.

Md Naimul Hoque, Wenbin He, Arvind Kumar Shekar, Liang Gou, Liu Ren. “Visual Concept Programming: A Visual Analytics Approach to Injecting Human Intelligence at Scale”, video, IEEE Transactions on Visualization and Computer Graphics 2022 (IEEE VIS 2022).
Summary: Enabling efficient image data programming using learned visual representations, user-defined labeling functions, and interactive visualizations, achieving improved semantic segmentation and image retrieval for autonomous driving.
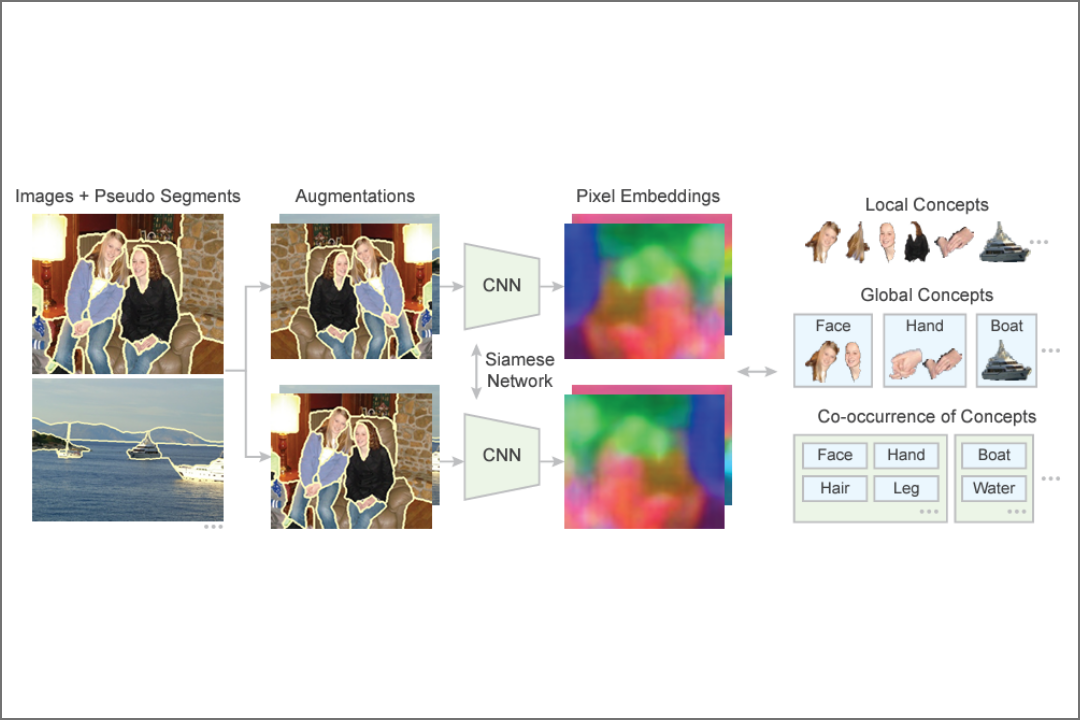
Wenbin He, William Surmeier, Arvind Kumar Shekar, Liang Gou, Liu Ren, “Self-supervised Semantic Segmentation Grounded in Visual Concepts”, International Joint Conference on Artificial Intelligence 2022 (IJCAI 2022).
Summary: A self-supervised pixel representation learning method for unsupervised semantic segmentation using visual concepts, achieving significant improvements over existing approaches on various datasets.

Arvind Kumar Shekar, Liang Gou, Liu Ren, Axel Wendt, “Label-free robustness estimation of object detection CNNs for autonomous driving applications”, International Journal of Computer Vision 2022 (IJCV 2022).
Summary: A label-free robustness metric for CNN object detectors in autonomous driving, quantifying detections' robustness to perturbations based on prediction confidences, achieving comparable results to ground truth aided scoring.

Sascha Hornauer, Ke Li, X Yu Stella, Shabnam Ghaffarzadegan, Liu Ren, “Unsupervised Discriminative Learning of Sounds for Audio Event Classification”, IEEE International Conference on Acoustics, Speech and Signal Processing 2021 (ICASSP 2021).
Summary: A fast and effective audio event classification model by pre-training unsupervised on audio data, achieving comparable performance to ImageNet pre-training and enabling knowledge transfer across audio datasets.

Zhenge Zhao, Panpan Xu, Carlos Scheidegger, Liu Ren, “Human-in-the-loop Extraction of Interpretable Concepts in Deep Learning Models”, video, IEEE Transactions on Visualization and Computer Graphics 2021 (IEEE VAST 2021).
Summary: A human-in-the-loop approach, ConceptExtract, for model interpretation, using active learning to generate user-defined concepts, facilitating understanding, and improving model performance through data augmentation.

Huan Song, Zeng Dai, Panpan Xu, Liu Ren, “Interactive Visual Pattern Search on Graph Data via Graph Representation Learning”, IEEE Transactions on Visualization and Computer Graphics 2021 (IEEE VAST 2021).
Summary: GraphQ, a visual analytics system using GNNs for subgraph pattern search in graphs, including NeuroAlign for node-alignment, showing improved accuracy and efficiency in analyzing program workflows and semantic scene graphs.

Wenbin He, Lincan Zou, Arvind Kumar Shekar, Liang Gou, Liu Ren, “Where Can We Help? A Visual Analytics Approach to Diagnosing and Improving Semantic Segmentation of Movable Objects”, video, IEEE Transactions on Visualization and Computer Graphics 2021 (IEEE VAST 2021).
Summary: VASS, a Visual Analytics approach, to improve semantic segmentation models in autonomous driving by analyzing spatial information and evaluating robustness through adversarial examples for critical object detection.

Jason Zink, Ryan Todd, Manjunath Kumbar, Arun Biyani, Xinyu Huang, and Liu Ren, “Virtual Visor: Adding Intelligence to LCD Displays to Selectively Block Sunlight”, video, SID International Conference on Display Technology 2021 (SID ICDT 2021, Best of Innovation Award at CES 2020).
Summary: The Bosch Virtual Visor uses liquid crystal display as a sun visor in vehicles, selectively blocking light to improve driver visibility by adapting to dynamic lighting conditions. It achieves a 90% improvement in visibility.

Kaiqiang Song, Bingqing Wang, Zhe Feng, Liu Ren, and Fei Liu. “Controlling the Amount of Verbatim Copying in Abstractive Summarization”, The AAAI Conference on Artificial Intelligence 2020 (AAAI 2020).
Summary: A neural summarization model that learns from single human abstracts to generate diverse summaries with different levels of copying, achieving competitive results in controlling verbatim copying.

Liang Gou, Lincan Zou, Nanxiang Li, Michael Hofmann, Arvind Kumar Shekar, Axel Windt, Liu Ren, "VATLD: A Visual Analytics System to Assess, Understand and Improve Traffic Light Detection", IEEE Transactions on Visualization and Computer Graphics 2020 (IEEE VAST 2020, Best Paper Award).
Summary: VATLD, a visual analytics system that uses disentangled representation learning and semantic adversarial learning to assess and improve the accuracy and robustness of traffic light detectors in autonomous driving, enabling minimal human interaction for actionable insights and practical implications for safety-critical applications.

Junhan Zhao, Zeng Dai, Panpan Xu, Liu Ren, “ProtoViewer: Visual Interpretation and Diagnostics of Deep Neural Networks with Factorized Prototypes”, IEEE Transactions on Visualization and Computer Graphics 2020 (IEEE VAST 2020).
Summary: A visual analytics framework for interpreting and diagnosing DNNs by factorizing latent representations into prototypes, providing global explanations, and supporting model comparisons, demonstrated with two DNN architectures and datasets.

Yao Ming, Panpan Xu, Furui Cheng, Huamin Qu, Liu Ren, "ProtoSteer: Steering Deep Sequence Model with Prototypes", video, IEEE Transactions on Visualization and Computer Graphics 2020 (IEEE VAST 2019, 2020).
Summary: ProtoSteer enabling experts to inspect, critique, and revise explainable AI (XAI) models (represented as a small set of prototypes) interactively with domain know-how for different AI applications (e.g., NLP, predictive diagnostics).

Yulin Yang, Benzun Pious Wisely Babu, Chuchu Chen, Guoquan Huang, Liu Ren, "Analytic Combined IMU Integration (ACI^2) For Visual Inertial Navigation", IEEE International Conference on Robotics and Automation 2020 (ICRA 2020).
Summary: Addressing key performance bottlenecks in visual-inertial sensor fusion: a modularized analytic combined IMU integrator (ACI^2) with elegant derivations for IMU integrations, bias Jabcobians and related covariances.

Yao Ming, Panpan Xu, Huamin Qu, Liu Ren, "Interpretable and Steerable Sequence Learning via Prototypes", video, ACM SIGKDD International Conference on Knowledge Discovery and Data Mining 2019 (ACM KDD 2019), Research Track, Oral.
Summary: A novel interpretable and steerable deep sequence model (ProSeNet) for explainable AI with natural explanations derived from case-based reasoning.

Benzun Pious Wisely Babu, Zhixin Yan, Mao Ye, Liu Ren, "On Exploiting Per-Pixel Motion Conflicts to Extract Secondary Motions", video, IEEE International Symposium on Mixed and Augmented Reality 2018 (ISMAR 2018).
Summary: A novel approach addressing motion conclit problems in visual-inertial sensor fusion, enabling better augmentation of virtual content attached to secondary motions for Ubiquitous Augmented Reality (AR).

Dongyu Liu, Panpan Xu, Liu Ren, "TPFlow: Progressive Partition and Multidimensional Pattern Extraction for Large-Scale Spatio-Temporal Data Analysis", video, IEEE Transactions on Visualization and Computer Graphics 2018 (IEEE VAST 2018, Best Paper Award).
Summary: A first visual analytics solution to handle multidimensional (>2D) spatial temporal data analysis for easy extraction and intuitive visualization of latent patterns based on a novel piecewise rank-one tensor decomposition algorithm.

Gromit Yeuk-Yin Chan, Panpan Xu, Zeng Dai, Liu Ren, "ViBR: Visualizing Bipartite Relations at Scale with the Minimum Description Length Principle", video, IEEE Transactions on Visualization and Computer Graphics 2018 (IEEE VAST 2018).
Summary: A novel visual summarization technique for interactive analysis of large bipartite graphs based on the minimum description length (MDL) principle and locality sensitive hashing (LSH).

Zhixin Yan, Mao Ye, and Liu Ren, "Dense Visual SLAM with Probabilistic Surfel Map", video, IEEE International Symposium on Mixed and Augmented Reality 2017 (ISMAR 2017), and selected for TVCG publication (IEEE Transactions on Visualization and Computer Graphics).
Summary: A novel map representation called Probabilistic Surfel Map (PSM) that provides globally consistent map of the environment for dense visual SLAM, leading to a drastic performance improvement (e.g, tracking errors) compared to the state of the art approach (e.g, σ-DVO)
Alsallakh Bilal, Amin Jourabloo, Mao Ye, Xiaoming Liu, and Liu Ren, "Do Convolutional Neural Networks Learn Class Hierarchy?", video, IEEE Transactions on Visualization and Computer Graphics 2017 (IEEE VAST 2017).
Summary: A novel explainable AI approach that can help to improve the performance of general CNN-based classifiers with ease by leveraging visual analytics to improve CNN model structure and identify issues in the training data


Yuanzhe Chen, Panpan Xu, and Liu Ren, "Sequence Synopsis: Optimize Visual Summary of Temporal Event Data", video, supplementary material, IEEE Transactions on Visualization and Computer Graphics 2017 (IEEE VAST 2017).
Summary: A novel event sequence summarization and visualization approach based on the minimum description length (MDL) principle addressing several key AI application areas (e.g., predictive diagnostics for connected vehicles)

Amin Jourabloo, Xiaoming Liu, Mao Ye, and Liu Ren, "Pose-Invariant Face Alignment with a Single CNN", video, International Conference on Computer Vision 2017 (ICCV 2017).
Summary: A novel large-pose face alignment method with fast end-to-end training in a single CNN

Panpan Xu, Honghui Mei, Liu Ren, and Wei Chen, “ViDX: Visual Diagnostics of Assembly Line Performance in Smart Factories”, video, IEEE Transactions on Visualization and Computer Graphics (IEEE VAST 2016, Best Paper Honorable Mention Award).
Summary: A first visual analytics approach to addressing the needs (e.g., easy process optimization and intuitive troubleshooting for manufacturing) of a new application domain-Industry 4.0 or Connected Industry

Bilal Alsallakh and Liu Ren, “PowerSet: A Comprehensive Visualization of Set Intersections”, video, IEEE Transactions on Visualization and Computer Graphics 2016 (IEEE Info VIS 2016).
Summary: A simple and novel set visualization approach for various kinds of big data analytics applications (e.g., predictive analytics)

Chao Du, Yen-Lin Chen, Mao Ye, and Liu Ren, “Edge Snapping-Based Depth Enhancement for Dynamic Occlusion Handling in Augmented Reality”, video, IEEE International Symposium on Mixed and Augmented Reality 2016 (full paper for ISMAR 2016).
Summary: A near real-time approach to dealing with dynamic occlusion handling challenges with high quality visual presentations for both video see-through and optics see-through AR applications

Benzun Wisely Babu, Soohwan Kim, Zhixin Yan, and Liu Ren, “σ-DVO: Sensor Noise Model Meets Dense Visual Odometry”, video, IEEE International Symposium on Mixed and Augmented Reality 2016 (full paper for ISMAR 2016).
Summary: A novel dense tracking approach by incorporating uncertainty modeling of depth measurements in the optimization framework of RGBD sensing for AR, leading to a drastic 25% error reduction compared to the state-of-the art solution

Jennifer Chandler, Lei Yang and Liu Ren, "Procedural Window Lighting Effects for Real-Time City Rendering", video, ACM SIGGRAPH Symposium on Interactive 3D Graphics and Games 2015 (I3D 2015).
Summary: A fast and scalable approach to addressing challenges in large scale night view rendering for big cities with applications in computer graphics and real-time geo-visualization for future infotainment systems

Mao Ye, Xianwang Wang, Ruigang Yang, Liu Ren, and Marc Pollefeys, "Accurate 3D Body Pose Estimation From a Single Depth Image", Proceedings of International Conference on Computer Vision 2011 (ICCV 2011).
Summary: A high accurate human pose estimation algorithm for entertainment applications that employ a depth sensor as input

Xinyu Huang, Liu Ren, and Ruigang Yang, "Image Deblurring for Less Intrusive Iris Capture", IEEE Computer Society Coference on Computer Vision and Pattern Recognition (CVPR 2009), June, 2009.
Summary: A long range and non-intrusive iris capture and recognition system featuring a novel image deblurring algorithm to handle the limitation of low cost hardware (patent granted)

Liu Ren, Alton Patrick, Alexei Efros, Jessica Hodgins, and James Rehg, "A Data-Driven Approach to Quantifying Natural Human Motion", ACM Transactions on Graphics (SIGGRAPH 2005), August, 2005.
Summary: The first approach to automatic human animation quality evaluation.

Liu Ren, Hanspeter Pfister and Matthias Zwicker, "Object Space EWA Surface Splatting: A Hardware Accelerated Approach to High Quality Point Rendering", Computer Graphics Forum 21(3)( EUROGRAPHICS 2002, Best Paper Nominee), September, 2002.
Summary: The first GPU-based approach to high quality point-based rendering with EWA filtering (patent granted)

Wei Chen, Liu Ren, Matthias Zwicker and Hanspeter Pfister, "Hardware-Accelerated Adpative EWA Volume Splatting", IEEE Visualization 2004, October, 2004.
Summary: The first GPU-based approach to high quality volume splatting with EWA filtering (patent granted)

Liu Ren, Gregory Sharknarovich, Jessica Hodgins, Hanspeter Pfister and Paul Viola, "Learning Silhouette Features for Control of Human Motion", ACM Transactions on Graphics (SIGGRAPH 2004), October, 2005.
Summary: A novel and low cost vision-based interface for "do-as-I-do" applications in entertainment industry